

集合类库图:
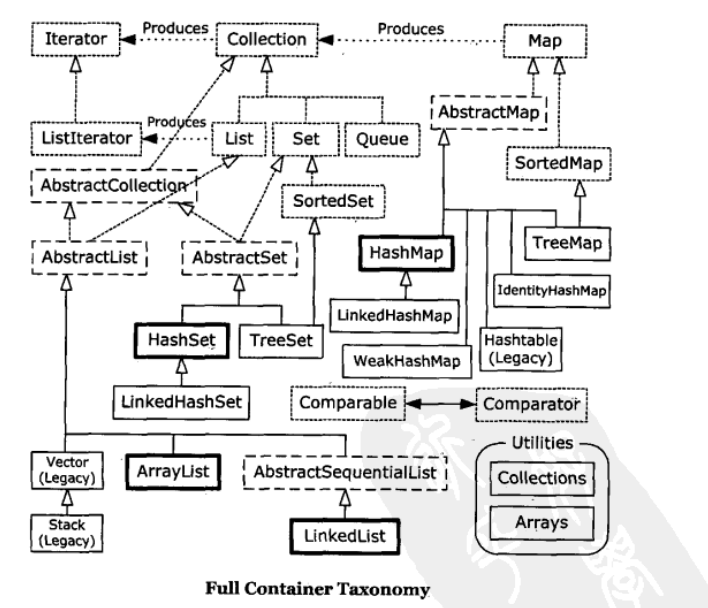
- 可选操作
执行各种不同的添加和移除的方法在Collection接口中都是可选操作,这意味着实现类并不需要为这些方法提供功能定义。简单来说,就是抽象类的某些派生类实现里,或者接口的某个实现类里面,某个方法是无意义的。
- 未获支持的操作
最常见的未获支持的操作,都来源于本和由固定尺寸的数据接口支持的容器。当你用Arrays.adList()将数组转换为List时,就会得到这样的容器。当然你也可以将它方法ArrayList将它转成一个支持所有方法的list:
public class Unsupported {
static void test(String msg, List<String> list) {
System.out.println("--- " + msg + " ---");
Collection<String> c = list;
Collection<String> subList = list.subList(1,8);
// Copy of the sublist:
Collection<String> c2 = new ArrayList<String>(subList);
try { c.retainAll(c2); } catch(Exception e) {
System.out.println("retainAll(): " + e);
}
try { c.removeAll(c2); } catch(Exception e) {
System.out.println("removeAll(): " + e);
}
try { c.clear(); } catch(Exception e) {
System.out.println("clear(): " + e);
}
try { c.add("X"); } catch(Exception e) {
System.out.println("add(): " + e);
}
try { c.addAll(c2); } catch(Exception e) {
System.out.println("addAll(): " + e);
}
try { c.remove("C"); } catch(Exception e) {
System.out.println("remove(): " + e);
}
// The List.set() method modifies the value but
// doesn't change the size of the data structure:
try {
list.set(0, "X");
} catch(Exception e) {
System.out.println("List.set(): " + e);
}
}
public static void main(String[] args) {
List<String> list =
Arrays.asList("A B C D E F G H I J K L".split(" "));
test("Modifiable Copy", new ArrayList<String>(list));
test("Arrays.asList()", list);
test("unmodifiableList()",
Collections.unmodifiableList(
new ArrayList<String>(list)));
}
} /* Output:
--- Modifiable Copy ---
--- Arrays.asList() ---
retainAll(): java.lang.UnsupportedOperationException
removeAll(): java.lang.UnsupportedOperationException
clear(): java.lang.UnsupportedOperationException
add(): java.lang.UnsupportedOperationException
addAll(): java.lang.UnsupportedOperationException
remove(): java.lang.UnsupportedOperationException
--- unmodifiableList() ---
retainAll(): java.lang.UnsupportedOperationException
removeAll(): java.lang.UnsupportedOperationException
clear(): java.lang.UnsupportedOperationException
add(): java.lang.UnsupportedOperationException
addAll(): java.lang.UnsupportedOperationException
remove(): java.lang.UnsupportedOperationException
List.set(): java.lang.UnsupportedOperationException
*///:~
因为Arrays.asList()会生成一个List,它基于一个固定大小的数组,仅支持哪些不会改变数组大小的操作,对它而言是有道理的。(可以看到代码中,是可以set的)
把Arrays.asList()的结果作为构造器的参数传递给任何Colelction(或者使用addAll,或者Collections.addAll()静态方法),这样就可以生成允许使用所有方法的普通容器。
Collections.unmodifiableList()产生补课修改的列表。(包括set)
- 17.6 Set和存储顺序
| 类 | 描述 |
|---|---|
| Set(interface) | 存入Set的每个元素都必须是唯一的,因为Set不保存重复元素。加入Set的元素必须定义equals()方法以确保对象的唯一性。Set不保证维护元素的次序 |
| HashSet | 为快速查找而设计的Set。存入HashSet的元素必须定义hashCode() |
| TreeSet | 保持次序的Set,底层为树结构。元素必须实现Comparable接口 |
| LinkedHashSet | 具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的顺序) |
- 17.7 队列
Queue在Java SE5中仅有的两个实现是LinkedList和PriorityQueuq,它们的差异在于排序行为而不是性能。(public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable)
public class QueueBehavior {
private static int count = 10;
static <T> void test(Queue<T> queue, Generator<T> gen) {
for(int i = 0; i < count; i++)
queue.offer(gen.next());
while(queue.peek() != null)
System.out.print(queue.remove() + " ");
System.out.println();
}
static class Gen implements Generator<String> {
String[] s = ("one two three four five six seven " +
"eight nine ten").split(" ");
int i;
public String next() { return s[i++]; }
}
public static void main(String[] args) {
test(new LinkedList<String>(), new Gen());
test(new PriorityQueue<String>(), new Gen());
test(new ArrayBlockingQueue<String>(count), new Gen());
test(new ConcurrentLinkedQueue<String>(), new Gen());
test(new LinkedBlockingQueue<String>(), new Gen());
test(new PriorityBlockingQueue<String>(), new Gen());
}
} /* Output:
one two three four five six seven eight nine ten
eight five four nine one seven six ten three two
one two three four five six seven eight nine ten
one two three four five six seven eight nine ten
one two three four five six seven eight nine ten
eight five four nine one seven six ten three two
*///:~
除了优先级队列,Queue将精确地按照元素被置于Queue中的顺序产生它们。
- 17.8.1 性能
HashMap使用的特殊的值,称作散列码,来取代对键的缓慢搜索。散列码是“相对唯一”的、用以代表对象的int值,它是通过将该对象的某些信息进行转换而成的。(后面会有详细介绍)
| 类 | 描述 |
|---|---|
| HashMap | Map基于散列表的实现(它取代了Hashtable) |
| LinkedHashMap | 类似于HashMap,但是迭代遍历它时,取得“键值对”的顺序是其插入次数,或者是最近最少使用(LRU)次数。只比HashMap慢一点,而在迭代访问时反而更快,因为它使用链表维护内部次序 |
| TreeMap | 基于红黑树的实现。内部是有序的 |
| WeakHashMap | 弱键(weak key)映射,允许释放映射所指向的对象 |
| ConcurrentHashMap | 一种线程安全的Map,但是不涉及同步加锁 |
| IdentityHashMap | 使用==代替equals()对key进行比较 |
总结来说,任何键都必须具有一个equals()方法,如果键被用于散列Map,那么它必须还具有恰当的hashCode()方法,如果键被用于TreeMap,那么它必须实现Comparable。
- 17.8.3 LinkedHashMap
可以在构造器中设定采用最近最少使用(LRC)算法:
public class LinkedHashMapDemo {
public static void main(String[] args) {
LinkedHashMap<Integer,String> linkedMap =
new LinkedHashMap<Integer,String>(
new CountingMapData(9));
print(linkedMap);
// Least-recently-used order:
linkedMap =
new LinkedHashMap<Integer,String>(16, 0.75f, true);
linkedMap.putAll(new CountingMapData(9));
print(linkedMap);
for(int i = 0; i < 6; i++) // Cause accesses:
linkedMap.get(i);
print(linkedMap);
linkedMap.get(0);//依然是原来的get(0),只是会更新LRU
print(linkedMap);
}
} /* Output:
{0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 6=G0, 7=H0, 8=I0}
{0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 6=G0, 7=H0, 8=I0}
{6=G0, 7=H0, 8=I0, 0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0}
{6=G0, 7=H0, 8=I0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 0=A0}
*///:~
在输出可以看到,键值对是以插入的顺序进行遍历的,甚至LRC算法的版本也是如此。
- 17.9 散列与散列码
当你自己创建用作HashMap的键的类,有可能会忘记在其中放置必需的方法,而这时通常会犯的一个错误:
public class Groundhog {
protected int number;
public Groundhog(int n) { number = n; }
public String toString() {
return "Groundhog #" + number;
}
}
public class Prediction {
private static Random rand = new Random(47);
private boolean shadow = rand.nextDouble() > 0.5;
public String toString() {
if(shadow)
return "Six more weeks of Winter!";
else
return "Early Spring!";
}
}
public class SpringDetector {
// Uses a Groundhog or class derived from Groundhog:
public static <T extends Groundhog>
void detectSpring(Class<T> type) throws Exception {
Constructor<T> ghog = type.getConstructor(int.class);
Map<Groundhog,Prediction> map =
new HashMap<Groundhog,Prediction>();
for(int i = 0; i < 10; i++)
map.put(ghog.newInstance(i), new Prediction());
print("map = " + map);
Groundhog gh = ghog.newInstance(3);
print("Looking up prediction for " + gh);
if(map.containsKey(gh))
print(map.get(gh));
else
print("Key not found: " + gh);
}
public static void main(String[] args) throws Exception {
detectSpring(Groundhog.class);
}
} /* Output:
map = {Groundhog #3=Early Spring!, Groundhog #7=Early Spring!, Groundhog #5=Early Spring!, Groundhog #9=Six more weeks of Winter!, Groundhog #8=Six more weeks of Winter!, Groundhog #0=Six more weeks of Winter!, Groundhog #6=Early Spring!, Groundhog #4=Six more weeks of Winter!, Groundhog #1=Six more weeks of Winter!, Groundhog #2=Early Spring!}
Looking up prediction for Groundhog #3
Key not found: Groundhog #3
*///:~
它无法找到数字3这个键,因为Groundhog自动继承自基类Object,所以这里使用Object的hashCode()方法生成散列码,而它默认是用对象的地址计算散列码的,因此两个的散列码是不同的。
但是只编写恰当的hashCode()方法也不够,因为HashMap是使用equals()来判断当前的键是否与表中存在的键相同。
正确的equals()方法必须满足于下列5个条件:
1. 自反性。对任意x,x.equals(x)一定为true。
2. 对称性。对任意x和y,如果y.equals(x)返回true,则x.equals(y)也返回true。
3. 传递性。对任意x、y、z,如果有x.equals(y)返回true,y.equals(z)返回true,则x.equals(z)一定返回true。
4. 一致性。对任意x和y,x.equals(y)无论调用多少次,返回结果应该保持一致。
5. 对任何不是null的x,x.equals(null)一定返回false。(调用instanceof可以悄悄地检查此对象是否为null)
默认的Object.equals()只是比较对象的地址,因此如果要使用自己的类作为HashMap的键,必须同时重载hashCode和equals()。
- 17.9.1 理解hashCode()
如果不为你的键覆盖hashCode()和equals(),那么使用散列的数据结构(HashSet,HashMap,LinkedHashSet或LinkedHashMap)就无法正确处理你的键。
使用散列的目的在于:想要使用一个对象来查找另一个对象。
- 17.9.2 为速度而散列
如果键没有按照任何特定顺序保存,所以只能使用简单的线性查询,而线性查询时最慢的查询方式。
散列中使用存储最快的数据结构数组来表示键的信息(是键的信息而不是键本身),因为数组不能调整容量,而我们希望在Map中保存数量不确定的值,因此数组不保存键本身,而是通过键对象生成一个数字,将其作为数组的下标,这个数字就是散列码。由定义在Object中的、且可能由你的类覆盖的hashCode()方法(在计算机科学的术语中成为散列函数)生成。
不同的键可以产生相同的下标,通常冲突是由外部链接处理:数组并不直接保存值,而是保存值的list。(如果能保证没有冲突,那可能就有了一个完美散列函数)因此,不是查询整个list,而是快速的跳到数组的某个位置,只对很少的元素进行比较,这边是HashMap会如此快的原因。
一个简单的散列Map:
public class SimpleHashMap<K,V> extends AbstractMap<K,V> {
// Choose a prime number for the hash table
// size, to achieve a uniform distribution:
static final int SIZE = 997;
// You can't have a physical array of generics,
// but you can upcast to one:
@SuppressWarnings("unchecked")
LinkedList<MapEntry<K,V>>[] buckets =
new LinkedList[SIZE];
public V put(K key, V value) {
V oldValue = null;
int index = Math.abs(key.hashCode()) % SIZE;
if(buckets[index] == null)
buckets[index] = new LinkedList<MapEntry<K,V>>();
LinkedList<MapEntry<K,V>> bucket = buckets[index];
MapEntry<K,V> pair = new MapEntry<K,V>(key, value);
boolean found = false;
ListIterator<MapEntry<K,V>> it = bucket.listIterator();
while(it.hasNext()) {
MapEntry<K,V> iPair = it.next();
if(iPair.getKey().equals(key)) {
oldValue = iPair.getValue();
it.set(pair); // Replace old with new
found = true;
break;
}
}
if(!found)
buckets[index].add(pair);
return oldValue;
}
public V get(Object key) {
int index = Math.abs(key.hashCode()) % SIZE;
if(buckets[index] == null) return null;
for(MapEntry<K,V> iPair : buckets[index])
if(iPair.getKey().equals(key))
return iPair.getValue();
return null;
}
public Set<Entry<K,V>> entrySet() {
Set<Entry<K,V>> set= new HashSet<Entry<K,V>>();
for(LinkedList<MapEntry<K,V>> bucket : buckets) {
if(bucket == null) continue;
for(MapEntry<K,V> mpair : bucket)
set.add(mpair);
}
return set;
}
public static void main(String[] args) {
SimpleHashMap<String,String> m =
new SimpleHashMap<String,String>();
m.putAll(Countries.capitals(25));
System.out.println(m);
System.out.println(m.get("ERITREA"));
System.out.println(m.entrySet());
}
} /* Output:
{CAMEROON=Yaounde, CONGO=Brazzaville, CHAD=N'djamena, COTE D'IVOIR (IVORY COAST)=Yamoussoukro, CENTRAL AFRICAN REPUBLIC=Bangui, GUINEA=Conakry, BOTSWANA=Gaberone, BISSAU=Bissau, EGYPT=Cairo, ANGOLA=Luanda, BURKINA FASO=Ouagadougou, ERITREA=Asmara, THE GAMBIA=Banjul, KENYA=Nairobi, GABON=Libreville, CAPE VERDE=Praia, ALGERIA=Algiers, COMOROS=Moroni, EQUATORIAL GUINEA=Malabo, BURUNDI=Bujumbura, BENIN=Porto-Novo, BULGARIA=Sofia, GHANA=Accra, DJIBOUTI=Dijibouti, ETHIOPIA=Addis Ababa}
Asmara
[CAMEROON=Yaounde, CONGO=Brazzaville, CHAD=N'djamena, COTE D'IVOIR (IVORY COAST)=Yamoussoukro, CENTRAL AFRICAN REPUBLIC=Bangui, GUINEA=Conakry, BOTSWANA=Gaberone, BISSAU=Bissau, EGYPT=Cairo, ANGOLA=Luanda, BURKINA FASO=Ouagadougou, ERITREA=Asmara, THE GAMBIA=Banjul, KENYA=Nairobi, GABON=Libreville, CAPE VERDE=Praia, ALGERIA=Algiers, COMOROS=Moroni, EQUATORIAL GUINEA=Malabo, BURUNDI=Bujumbura, BENIN=Porto-Novo, BULGARIA=Sofia, GHANA=Accra, DJIBOUTI=Dijibouti, ETHIOPIA=Addis Ababa]
*///:~
- 17.9.3 覆盖hashCode()
设计hashCode()时最重要的因素就是:无论何时,对同一个对象调用hashCode()都应该生成相同的值。此外,也不应该使hashCode()依赖于具有唯一性的对象信息,尤其是使用this的值。
对于String来说,它们的hashCode()是基于String的内容的,不管是=,还是new,只要内容一样,hashCode()的结果就是一样的。
好的hashCode()应该产生分布均匀的散列码。
Joshua Bloch为怎样写出一份像样的hashCode()给出了基本的指导:
1. 对int变量result赋予某个非0常值,例如17.
2. 对对象内每个有意义的域f(即每个可以做equals()操作的域)计算出一个int散列码c:
| 域类型 | 计算 |
|---|---|
| boolean | c = (f?0:1) |
| byte、char、short或int | c=(int)f |
| long | c = (int)(f^(f>>>32)) |
| float | c = Float.floatToIntBits(f) |
| double | c = long l =Double.doubleToLongBits(f); c = (int)(l^(l>>>32)) |
| Object | c = f.hashCode() |
| 数组 | 对每个元素应用上诉规则 |
3. 合并计算得到的散列码:result=37*result+c
4. 返回result。
5. 检查hashCode()最后生成的结果,确保相同的对象有相同的散列码
一个简单的例子:
public class CountedString {
private static List<String> created =
new ArrayList<String>();
private String s;
private int id = 0;
public CountedString(String str) {
s = str;
created.add(s);
// id is the total number of instances
// of this string in use by CountedString:
for(String s2 : created)
if(s2.equals(s))
id++;
}
public String toString() {
return "String: " + s + " id: " + id +
" hashCode(): " + hashCode();
}
public int hashCode() {
// The very simple approach:
// return s.hashCode() * id;
// Using Joshua Bloch's recipe:
int result = 17;
result = 37 * result + s.hashCode();
result = 37 * result + id;
return result;
}
public boolean equals(Object o) {
return o instanceof CountedString &&
s.equals(((CountedString)o).s) &&
id == ((CountedString)o).id;
}
public static void main(String[] args) {
Map<CountedString,Integer> map =
new HashMap<CountedString,Integer>();
CountedString[] cs = new CountedString[5];
for(int i = 0; i < cs.length; i++) {
cs[i] = new CountedString("hi");
map.put(cs[i], i); // Autobox int -> Integer
}
print(map);
for(CountedString cstring : cs) {
print("Looking up " + cstring);
print(map.get(cstring));
}
}
} /* Output: (Sample)
{String: hi id: 4 hashCode(): 146450=3, String: hi id: 1 hashCode(): 146447=0, String: hi id: 3 hashCode(): 146449=2, String: hi id: 5 hashCode(): 146451=4, String: hi id: 2 hashCode(): 146448=1}
Looking up String: hi id: 1 hashCode(): 146447
0
Looking up String: hi id: 2 hashCode(): 146448
1
Looking up String: hi id: 3 hashCode(): 146449
2
Looking up String: hi id: 4 hashCode(): 146450
3
Looking up String: hi id: 5 hashCode(): 146451
4
*///:~
- 17.10.2 对list的选择
最佳的做法可能是将ArrayList(随机访问快)作为默认首选,只有你需要使用额外的功能,或者当程序的性能因为从表中进行插入和删除而变差的时候,才去选择LinkedList。如果使用的是固定数量的元素,那么既可以使用背后由数组支撑的List(Arrays.asList()产生的列表),也可以选择真正的数组。
- 17.10.4 对Set的选择
HashSet的性能基本上总是比TreeSet好,当需要一个排好序的Set时,才应该使用TreeSet。因为TreeSet内部结构支持排序,因此用TreeSet迭代通常比用HashSet要快。
对于插入操作,LinkedHashSet比HashSet的代价更高,这是由维护链表所带来额外开销造成的。
- 17.10.5 对Map的选择
Hashtable的性能大体上与HashMap相当,因为HashMap是用来替代Hashtable的。
使用Map时,你的第一选择应该是HashMap,只有在你要求Map始终保持有序时,才需要使用TreeMap.
HashMap的性能因子
1. 容量:表中的桶位数
2. 初始容量:表在创建时所拥有的桶位数。
3. 尺寸:表中当前存储的项数。
4. 负载因子:尺寸/容量。当负载情况达到该因子的水平是,容器将自动增加其容量(桶位数),实现方式是史容量大致加倍,并重新将现有对象分布到新的桶位集中(这被称为再散列)。默认的负载因子是0.75。更高的负载因子可以降低表所需要的空间,但是会增加查找代价。
- 17.11.3 Collection或Map的同步控制
Java容器类类库采用快速保存机制,她会探查容器上任何除了你的进程所进行的操作以外的所有变化,一旦它发现其他进程修改了容器,就会立刻抛出ConcurrentModificationException异常。
- 17.12 持有引用
强引用(StrongReference)
强引用是使用最普遍的引用。如果一个对象具有强引用,那垃圾回收器绝不会回收它。当内存空间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足的问题。
软引用(SoftReference)
如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。
软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收器回收,Java虚拟机就会把这个软引用加入到与之关联的引用队列中。
弱引用(WeakReference)
弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。
弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。
虚引用(PhantomReference)
“虚引用”顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。
虚引用主要用来跟踪对象被垃圾回收器回收的活动。虚引用与软引用和弱引用的一个区别在于:虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之 关联的引用队列中。
- 17.12.1 WeakHashMap
和HashMap一样,WeakHashMap 也是一个散列表,它存储的内容也是键值对(key-value)映射,而且键和值都可以是null。
不过WeakHashMap的键是“弱键”。在 WeakHashMap中,当某个键不再正常使用时,会被从WeakHashMap中被自动移除。更精确地说,对于一个给定的键,其映射的存在并不阻止垃圾回收器对该键的丢弃,这就使该键成为可终止的,被终止,然后被回收。某个键被终止时,它对应的键值对也就从映射中有效地移除了。
这个“弱键”的原理呢?大致上就是,通过WeakReference和ReferenceQueue实现的。WeakHashMap的key是“弱键”,即是WeakReference类型的;ReferenceQueue是一个队列,它会保存被GC回收的“弱键”。实现步骤是:
- 新建WeakHashMap,将“键值对”添加到WeakHashMap中。实际上,WeakHashMap是通过数组table保存Entry(键值对);每一个Entry实际上是一个单向链表,即Entry是键值对链表。
- 当某“弱键”不再被其它对象引用,并被GC回收时。在GC回收该“弱键”时,这个“弱键”也同时会被添加到ReferenceQueue(queue)队列中。
- 当下一次我们需要操作WeakHashMap时,会先同步table和queue。table中保存了全部的键值对,而queue中保存被GC回收的键值对;同步它们,就是删除table中被GC回收的键值对。
这就是“弱键”如何被自动从WeakHashMap中删除的步骤了
相关文章